はじめに
この記事は Softbank AI部 Advent Calendar 2019の20日目の記事です。
なお、当ブログでの発言は個人の見解であり、所属する組織の公式見解ではありません
関連Slackに参加させて頂いている事もありAdvent Calendarにも参加させて頂きました。
今回のAdvent Calendarでは、私自身はAIとかよく分かんないAIド素人なのと本業もたいしたことしているわけでもないので深い話もできませんが、Tensorflow basedのSpleeterについて触れてみたいと思います。
当初は先日アメリカはラスベガスでで開催され個人の旅行がてら参加したAWS re:invent2019について書こうかも悩んでいましたが、メインはSpleeterを触ってみたについてを書くとして、最後におまけにほんの少しだけAWS re:invent 2019について書く形で欲張り記事でいきたいと思います。
事前にSpleeterの日本語記事はあまり探してなかったのですが、調べるとさすがにそれなりに記事がありましたので何番煎じかわかりませんがやっていきたいと思います。
Spleeterの話
Overview
Deezerという音楽配信をメインとしている会社がMITライセンスで公開しているツールがSpleeterです。
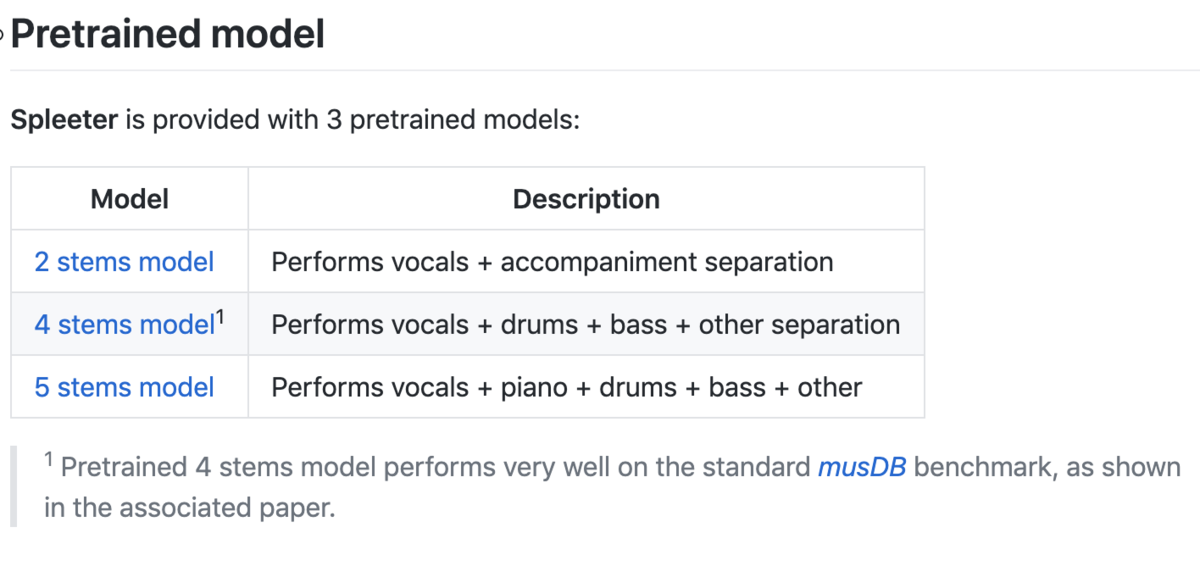
Spleeterで何ができるかというと、機械学習による学習済みモデルを利用した音声ソースの分離ができるもので、楽曲からVocalのみを抽出したり、Vocal、ピアノ、ドラム、その他の様にでき、抽出パターンが3パターン用意されています。
SpleeterはTensorflowに基づいたPythonライブラリの形式で提供され、2、4、5ステムに分離できる事前学習済みモデルを備えています。
*Github Wikiより引用
で、それ抽出してどうするのって言うところですが、音楽学習の為の耳コピー用に楽曲のみにしたり個人的にカラオケ楽曲作成とかでしょうか。
ちなみに、Native Instrumentsという会社でStemsという音楽ファイルフォーマットがあって海外の大手専門音楽配信サイトなどで売られてはいるのですが、これに近いフォーマットが個々のファイルで出力されるといったほうがわかりやすい方がいるかもしれません。
ただ実際のNative Instruments Stemsはmp4フォーマットの中に4トラック分が格納されていたと思うのでその辺は違いますので、そのままStemsへは取り込めません。(おそらく)
なお、Spleeterの詳細についての日本語Wikiが存在するので初めに読まれると良いと思います。
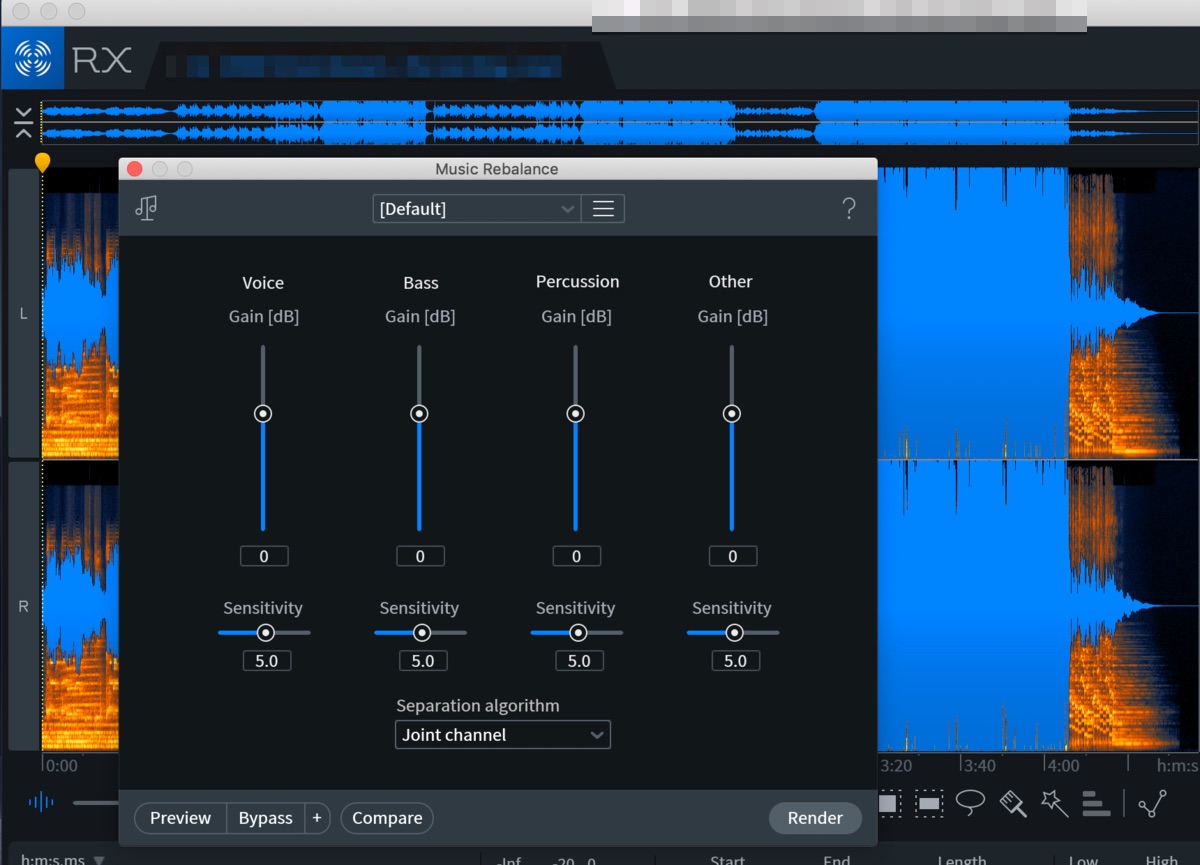
また、使用方法は全く異なりますが、こちらもMLを使っているらしく同様な機能を有しているDAWのプラグインiZotope RXがSpleeterとの話の引き合いに出されている気がします。興味がある方はぜひ調べてみてください。
iZotope RXを所有していますが、こいつのMusic Rebalance機能(予め設定されたパートで音量調整ができます)も凄いです。音を聴きながらフェダーを調整するだけです。
Spleeterもgithubのissiueをみる感じですとVST化もありそうな感じです。
あ、全然関係無い話しを長く書いてしまいました。話しを戻したいと思います。
必要実行環境は?
実行環境についてはcondaが用意されているため、conda実行環境を整えればMacはもちろんWindows環境でも利用はできます。
ただ、Windows環境はconda環境が推奨との事ですが、MacはPython pipでも行けそうなのでanaconda環境とかが嫌な方はpipでも良いと思います。
その他、Docker Imageも準備されているようなのですが、OfficialのDocker Imageはまだ無いようです。
一応Docker Hubにも3種類くらいのImageはアップロードされているようですが。
Documentを見るとDockerだとtrainingからevaluationの流れできるようです。
と記事を書いてる時にgithubのコードを見てたらDockerfileも含まれていましたね。。
実際に動かしてみよう
Mac環境でcondaは使わず、Python pipを使った方法ですすめます。
なおPythonバージョンは3.7.5環境です。
環境を切りたい方はpyenv使うなりpipenv使うなりご自由にどうぞ。
なお、Spleeterのインストール方法はこちらに書かれています。
最初にffmpegも必要になりますので入ってない人は brew などで入れます
❯❯❯ brew install ffmpeg
githubのレポジトリをclone
❯❯❯ git clone https://github.com/Deezer/spleeter ❯❯❯ cd spleeter
spleeterをpip install
❯❯❯ pip install spleeter
まっさらなPCでインストールしたため、以下な感じで依存関係で色々インストールされました。
Installing collected packages: future, ffmpeg-python, numpy, scipy, norbert, six, python-dateutil, pytz, pandas, certifi, chardet, urllib3, idna, requests, keras-preprocessing, absl-py, werkzeug, grpcio, protobuf, markdown, tensorboard, termcolor, h5py, keras-applications, astor, tensorflow-estimator, wrapt, gast, google-pasta, tensorflow, spleeter
早速githubのレポジトリに入ってるサンプル(audio_example.mp3)を処理してみる
spleeter separate -i [Stems化対象ファイル] -p spleeter:[2 or 4 or 5]stems -o [出力先フォルダ]
❯❯❯ spleeter separate -i audio_example.mp3 -p spleeter:2stems -o outputs INFO:spleeter:Downloading model archive https://github.com/deezer/spleeter/releases/download/v1.4.0/2stems.tar.gz INFO:spleeter:Validating archive checksum INFO:spleeter:Extracting downloaded 2stems archive INFO:spleeter:2stems model file(s) extracted INFO:spleeter:File outputs/audio_example/accompaniment.wav written INFO:spleeter:File outputs/audio_example/vocals.wav written ❯❯❯
なんとこれだけ!!
Fileの書き込みが完了すれば完了。
conda環境がめんどくさい人はpipするだけでもさくっといけます!
抽出が完了したらファイルを再生してみよう!
おおちゃんと抽出されてる!(実際の音源はみなさんの手元で確認してみましょう)
demo音源以外も試してみてジャンルにもよるとは思いますが、demoより精度が高い分離ができた事もありました。
更に5つつのStemsに分割するとこんな感じの出力結果
❯❯❯ spleeter separate -i audio_example.mp3 -p spleeter:5stems -o outputs INFO:spleeter:Downloading model archive https://github.com/deezer/spleeter/releases/download/v1.4.0/5stems.tar.gz INFO:spleeter:Validating archive checksum INFO:spleeter:Extracting downloaded 5stems archive INFO:spleeter:5stems model file(s) extracted INFO:spleeter:File outputs/audio_example/vocals.wav written INFO:spleeter:File outputs/audio_example/drums.wav written INFO:spleeter:File outputs/audio_example/piano.wav written INFO:spleeter:File outputs/audio_example/bass.wav written INFO:spleeter:File outputs/audio_example/other.wav written
こちらも問題ありませんでした。
簡単にお試しだけする
環境を用意する前にどんなのかみてみたいという方は、
Google colaboratoryが用意されているのでこちらで体験してみると言う事もできます。
分離後の音源も聞く事ができますよ!
Google Colab
Spleeterおまけ
この手の音源分離を行うためのデータセットがあります。
re:invent 2019の話

場所は毎年同じのアメリカはネバダ州のラスベガス。
今年は水曜に雨が降ったりで気温も去年よりはやや寒い印象を受けました。
今年の新サービス発表などは、去年に比べると印象が弱いものではありましたが、AIやHPCの分野のサービスが主だってたなという個人的印象でした。
なお、全体では約70ほどの新サービスが発表という形になっています。
ML系に興味がある方が辿りつくかもしれませんので、ML系の今回のアップデートSummaryの資料リンクをつけておきたいと思います。
現在私は基本的にはITインフラエンジニア業がメインでお仕事させて頂いておりますが、上のレイヤーのITエンジニアだけでなくインフラ寄りのITエンジニアももっとre:inventに参加してみると良いのではと思いました。
たとえば、AWS HPCの構成みてみるとサーバ間の構成(Fabric的なECMP構成だったと思います)やElastic Fabric AdapterだったりNW系のサービスもAWSには沢山ありますし、ITインフラ側の人間としても興味深い発見やクラウドでの使われ方などを知る事ができると思います。2019ですとOutpostsなんかもGAとなりましたし。(セッションは基本的に英語ですが)
あとは、これは業務ロールに関係しないですが、AWS好きの方は一度はあの現地の空気感(Keynoteの反応、セッションの人気度やActivityなど)を感じに行くだけでも得るものがあるかもしれません。
忘れてましたが、re:invent参加前にはAWS Certificateを取得されてから行くと、会場でCertificate取得者専用のswagが貰えたりLounge(常にドリンクやおやつがあります)が使えるのでおすすめです。